CDP:Storage Indexパターン
提供:AWS-CloudDesignPattern

インターネットストレージの効率化
目次 |
解決したい課題
インターネットストレージはデータが分散配置されているので耐久性も可用性も高い。ただ、インターネット経由でアクセスすることになるのでオンプレミスに比べて一般に応答性能は低い。また、高度な検索機能は用意されていない場合があるので、特定ユーザーのデータ一覧を取得したり、ある日付範囲のデータを取得したりする場合、アプリケーション側で工夫が必要になる。
クラウドでの解決/パターンの説明
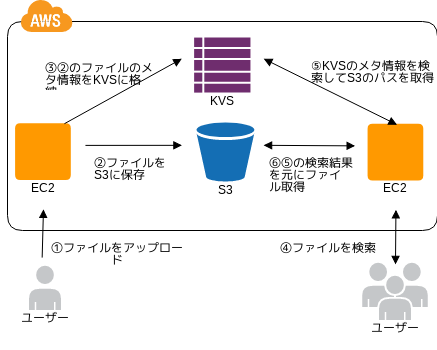
インターネットストレージにデータを格納する際、同時に検索性能の高いKVSへメタ情報を格納し、その情報をインデックスとして利用する。検索時はKVSを用い、得られた結果を基にインターネットストレージへアクセスする。
実装
(手順)
- S3へデータを格納した後、S3のメタ情報(キー、パス、データサイズ、格納時間など)をSimpleDBもしくはDynamoDBに格納する。
- 検索や集計を行う際、SimpleDBやDynamoDBを利用して処理を行う。
- SimpleDBやDynamoDBの処理結果を基に、S3のデータを取得する。
- またAWS Lambdaを利用する事により、S3にファイルがアップロードされたことをトリガーにして自動的にインデックス化を実施できる。(EC2インスタンス無しでインデックス化が可能)
構造
利点
- 堅牢で大容量なストレージ機能と、高い検索性の両方を利用できる。
注意
- S3内のデータと、KVSのメタ情報にミスマッチが発生すると、正しい検索結果が得られない。データの登録とメタ情報の登録は、必ず同時に行う。
その他
- 「Web Storage」パターンを参照。